Feedback-Driven Context Pipelines (Rlhf + RAG)
Answer Block
Answer Block: Every time you start a new session with an AI agent, it forgets everything. The bug it introduced yesterday? Gone. The coding pattern you corrected three times?
The Problem: AI Agents Have Amnesia
Every time you start a new session with an AI agent, it forgets everything. The bug it introduced yesterday? Gone. The coding pattern you corrected three times? Forgotten. The architectural decision you debated for an hour? Erased.
This is the fundamental limitation of stateless LLM sessions — and in 2026, the best AI engineering teams are solving it not with fine-tuning, but with feedback-driven context pipelines.
What We Built
Our trading system uses a 4-stage pipeline that captures every interaction signal and feeds it back into future sessions:
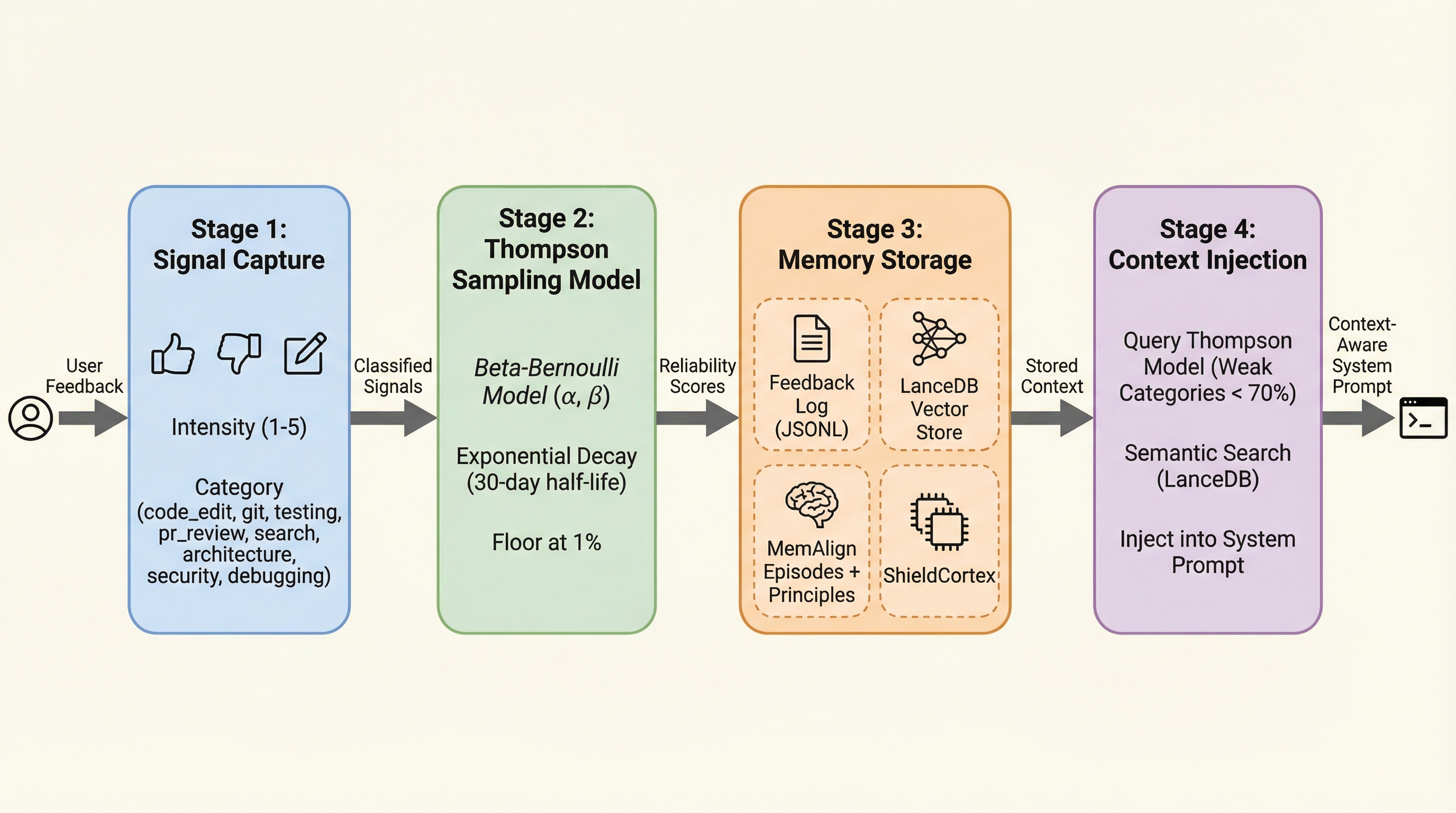
Stage 1: Signal Capture
Hooks detect user feedback automatically — thumbs up, thumbs down, text corrections, frustration signals (multiple exclamation marks, strong negative words). Each signal is classified by:
- Intensity (1-5 scale)
- Category (code_edit, git, testing, architecture, security, debugging)
Stage 2: Thompson Sampling Model
Instead of simple averages, we use Thompson Sampling — a Bayesian approach that maintains Beta distributions per category:
code_edit: alpha=350.4, beta=1.0 → 99.7% reliability
git: alpha=216.9, beta=2.0 → 99.1% reliability
testing: alpha=107.4, beta=2.0 → 98.2% reliability
Key design choices:
- Exponential decay with 30-day half-life — recent feedback matters more
- Floor at 1% — critical lessons never fully forgotten
- Per-category tracking — the agent knows it’s weak at git operations but strong at code editing
Stage 3: Memory Storage (4 Stores)
| Store | Format | Purpose |
|---|---|---|
| Feedback Log | JSONL | Raw append-only event log |
| LanceDB | Vector embeddings | Semantic similarity search |
| MemAlign | Episodes + Principles | Distilled reusable rules |
| ShieldCortex | SQLite | Persistent cross-session memory |
Stage 4: Context Injection
On every session start, hooks:
- Query Thompson model for weak categories (below 70% success)
- Retrieve semantically similar past failures from LanceDB
- Inject both into the system prompt
The agent sees its past mistakes before acting — not after.
How This Compares to 2026 State of the Art
We researched what the best teams are building:
Mem0 (Production-Ready Agent Memory): Uses LLM-based extraction to convert conversations into structured facts, then consolidates with ADD/UPDATE/DELETE/NOOP operations. Achieves 91% lower latency than full-context approaches.
OpenAI Agents SDK: Implements a 3-layer memory model — structured profile, global memory notes, and session memory — with explicit precedence rules and async consolidation.
Reflective Agents (2026 Trend): Process reward models give feedback on each reasoning step, not just final output. Agents develop emergent self-correction behaviors.
Where We’re Ahead
- Thompson Sampling per category — mathematically optimal for small-sample reliability tracking. Most teams use simple averages.
- Exponential decay — recent feedback weighted more than old feedback, with a floor so critical lessons persist.
- Category-level granularity — the agent knows exactly which task types it struggles with.
Where We Need to Catch Up
- Structured fact extraction — we store raw feedback; Mem0 extracts structured facts via LLM
- Memory consolidation — we append-only; Mem0 deduplicates with ADD/UPDATE/DELETE
- 3-layer memory model — we have single-layer injection; OpenAI recommends profile + global + session
The TARS Connection
All LLM calls in this pipeline route through Tetrate Agent Router Service (TARS):
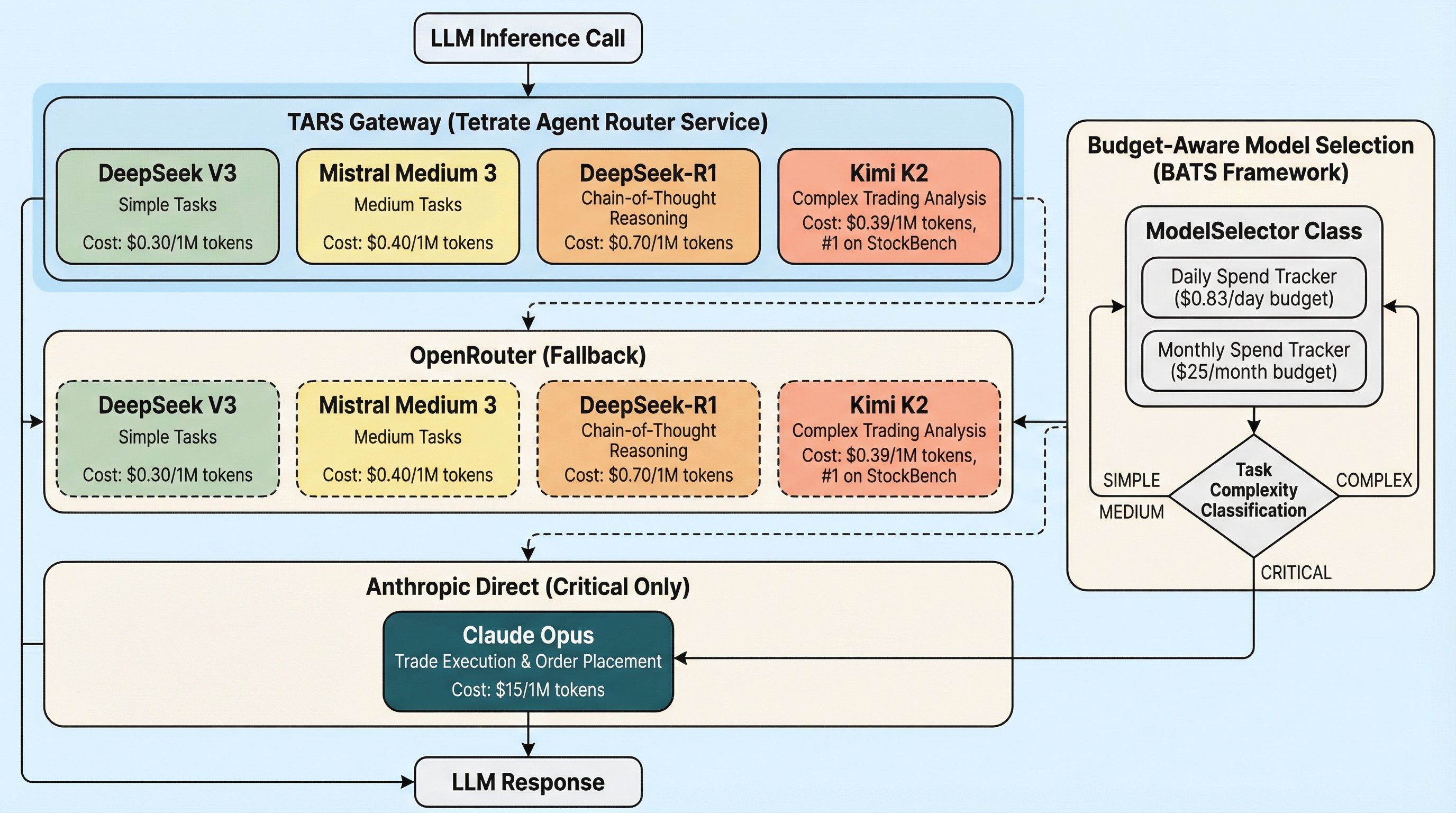
When the feedback pipeline needs to extract structured facts from raw feedback (our next upgrade), that extraction LLM call will route through TARS — getting automatic fallback, budget enforcement, and telemetry. The gateway doesn’t just serve trading decisions; it serves the learning system itself.
Key Takeaway
You don’t need to fine-tune a model to make it learn. Structured context injection — capturing feedback, storing it semantically, and prepending relevant history into every session — achieves behavioral adaptation that’s immediate, auditable, and works with any foundation model.
The agent’s weights don’t change. But its behavior does.
This post is part of our AI Trading Journey — building a system that learns from every mistake on the path to financial independence.
Evidence: https://github.com/IgorGanapolsky/trading