Tetrate Buildathon: AI Trading System Entry
Answer Block
Answer Block: The Tetrate AI Buildathon challenges participants to build or enhance applications using TARS (Tetrate Agent Router Service) — an AI gateway that routes LLM cal
The Buildathon
The Tetrate AI Buildathon challenges participants to build or enhance applications using TARS (Tetrate Agent Router Service) — an AI gateway that routes LLM calls across multiple providers.
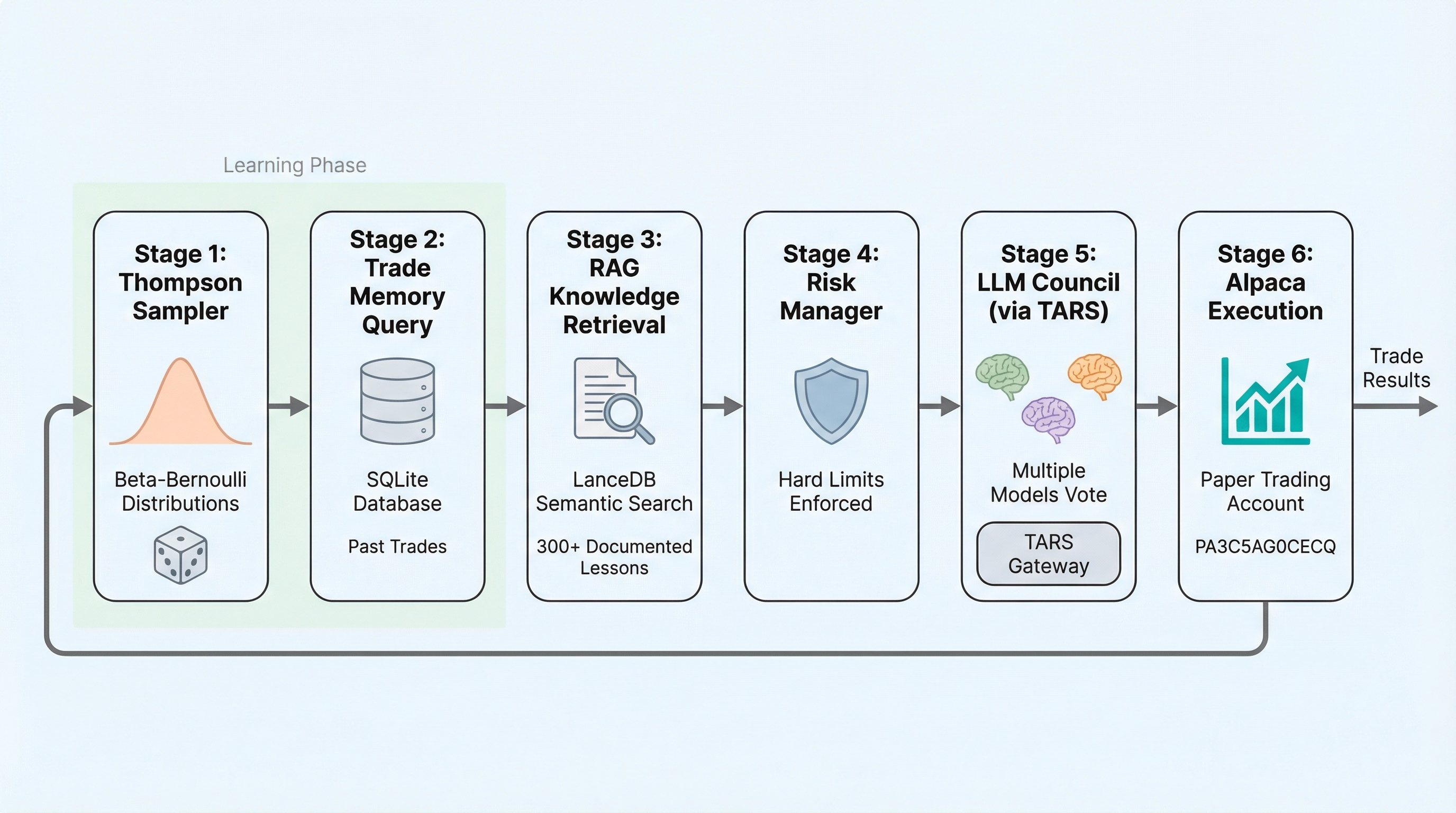
We’re bringing an existing system: an autonomous AI trading system that executes SPY iron condor options strategies with $100K in paper capital. The system already had multi-model routing built locally. TARS lets us move that routing to a centralized gateway with features we can’t replicate locally.
What We Already Had
Before the buildathon, our system included:
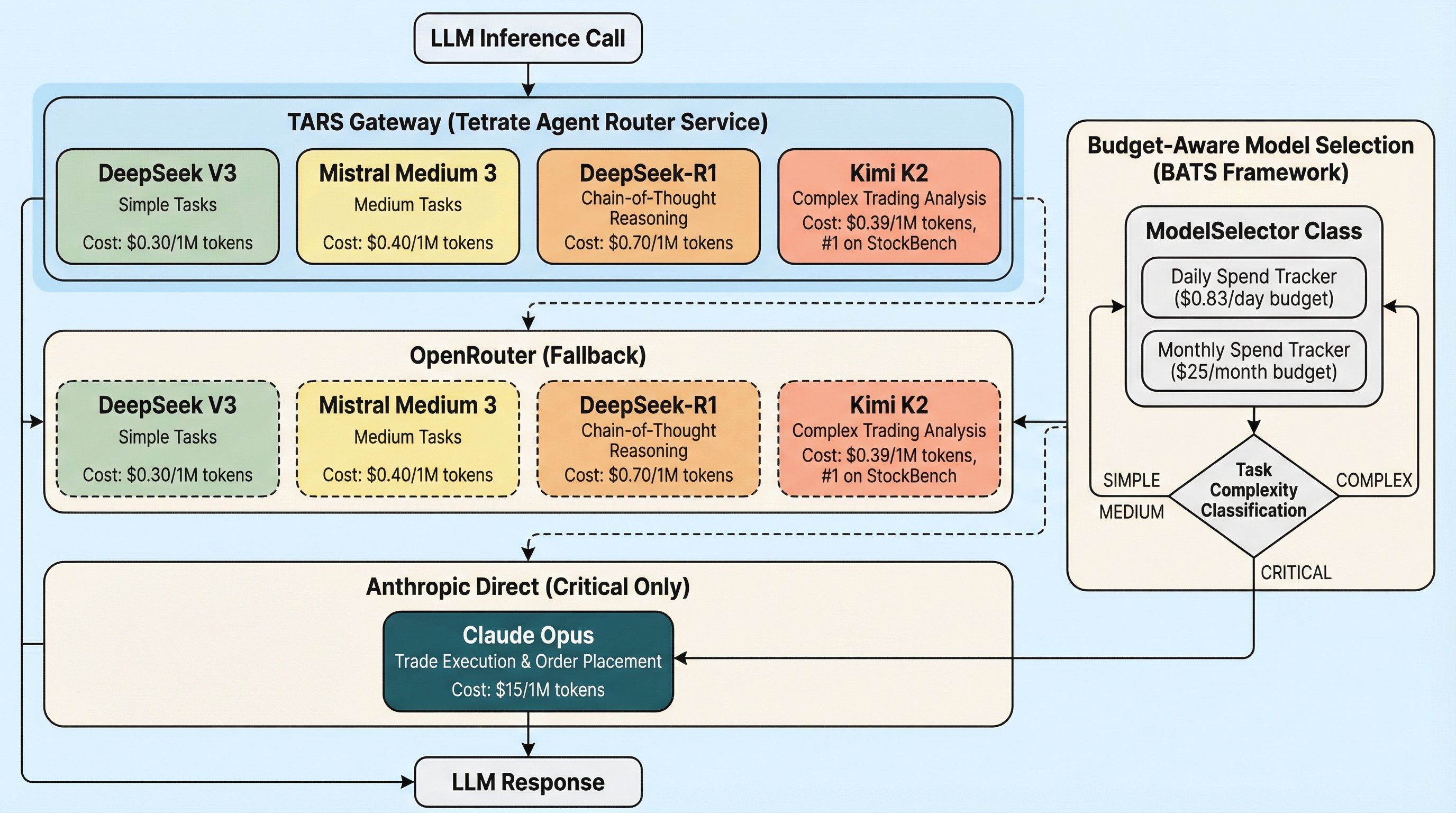
- Budget-Aware Model Selection (BATS) — routes tasks to the cheapest capable model ($25/month vs $500+)
- 5 LLM models across 3 providers (DeepSeek, Mistral, Kimi K2, DeepSeek-R1, Claude Opus)
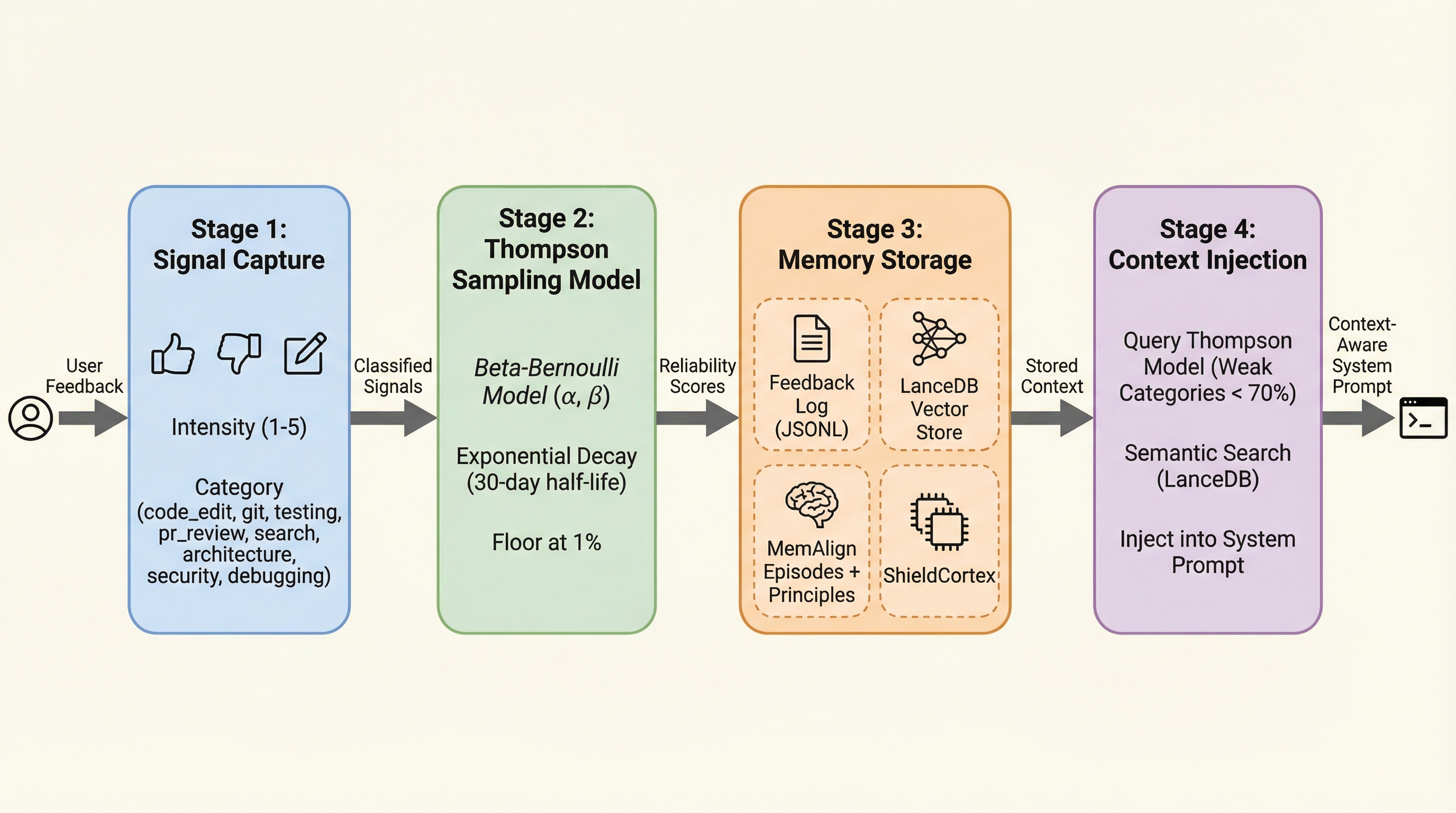
- Feedback-driven context pipeline — Thompson Sampling + LanceDB + MemAlign for continuous learning
- 84 GitHub Actions workflows — self-healing CI that monitors, fixes, and learns autonomously
- 170+ documented lessons — every failure recorded, indexed, and searchable via semantic search
What TARS Adds
| Feature | Before (Local) | After (TARS) |
|---|---|---|
| Fallback routing | Code-level fallback chain in model_selector.py |
Gateway-level auto-failover across providers |
| Budget enforcement | Local tracking, resets on restart | Server-side per-token budgets, persistent |
| Traffic splitting | Not possible | A/B test model quality (e.g., 90% Kimi K2 / 10% new model) |
| Telemetry | Manual logging | Centralized request logs, usage dashboards, cost tracking |
| MCP profiles | N/A | Curated tool subsets for different trading agents |
| Key management | Multiple env vars per provider | Single TARS key, BYOK for each provider behind the gateway |
The integration point is minimal — two environment variables:
LLM_GATEWAY_BASE_URL=https://api.router.tetrate.ai/v1
TETRATE_API_KEY=sk-your-key
Every OpenAI-compatible call in the system routes through TARS with zero code changes.
Architecture
What We Built Today
In one buildathon day:
- README rewrite — documented the real architecture with TARS integration for judges
- 3 PaperBanana diagrams — auto-generated publication-quality architecture visuals via Gemini
- 2026 SOTA comparison — researched how our feedback pipeline compares to Mem0, OpenAI Agents SDK, and state-of-the-art agent memory systems
- 4 blog posts — this one, plus deep-dives on feedback pipelines, TARS routing, and PaperBanana automation
- 3 Claude Code skills —
/generate-diagram,/generate-plot,/update-diagramsfor repeatable diagram generation
Key Insight
The biggest value of TARS isn’t replacing what we already built — it’s centralizing it. Our local model_selector.py does budget-aware routing well. But TARS adds the layer above: gateway-level failover, server-side budget persistence, traffic splitting for model evaluation, and a telemetry dashboard that works across all our agents without custom instrumentation.
For a trading system where reliability directly equals money, that centralization matters.
Built for the Tetrate AI Buildathon. Full source code at github.com/IgorGanapolsky/trading.